SeaMeet Speaker Identification: Identyfikuj i oznaczaj mówców w transkryptach spotkań osobistych
Spis Treści
Transkrypcja spotkania osobistego (gdzie uczestnicy są w tym samym pomieszczeniu) może być wyzwaniem. Jeśli używasz Google Meet do nagrywania sesji, wszystkie głosy są przechwytywane na jednym kanale audio, co utrudnia rozpoznanie, kto co powiedział. Funkcja Speaker Identification SeaMeet została zaprojektowana, aby rozwiązać ten problem. Wykorzystuje zaawansowaną AI do rozróżniania mówców w transkrypcie spotkania i pozwala przypisać prawidłowe imiona, co skutkuje jasnym, czytelnym zapisem dyskusji.
Dlaczego identyfikacja mówców jest ważna dla spotkań
W spotkaniu z wieloma mówcami surowy transkrypt może szybko stać się mylący – możesz zobaczyć długi blok tekstu bez żadnej wskazówki o zmianie mówcy. Ważne jest, aby wiedzieć, kto powiedział każdy komentarz dla dokładnych notatek i działań następczych. SeaMeet rozwiązuje to poprzez diaryzację audio – proces AI, który wykrywa, kiedy różni ludzie mówią. Określając liczbę uczestników, SeaMeet może podzielić transkrypt na segmenty dla każdego mówcy (np. Speaker 1, Speaker 2, Speaker 3). Ta funkcja działa najlepiej dla spotkań z około 2–6 osobami dla optymalnej dokładności.
Identyfikacja mówców w spotkaniu osobistym
Używanie narzędzia Identify Speakers SeaMeet jest proste. Zaczynasz od wskazania, ile osób było na spotkaniu. SeaMeet następnie ponownie podzieli cały transkrypt według tej liczby. System przechodzi przez nagranie i grupuje dialog według mówcy, oznaczając każdy segment nazwą zastępczą jak Speaker 1, Speaker 2, itp. Podczas tego procesu identyfikacji nie musisz czekać – możesz opuścić interfejs spotkania i wrócić później, ponieważ SeaMeet będzie kontynuował przetwarzanie w tle. Po zakończeniu zobaczysz transkrypt schludnie podzielony i oznaczony według różnych mówców, dając Ci początkową diaryzację rozmowy.
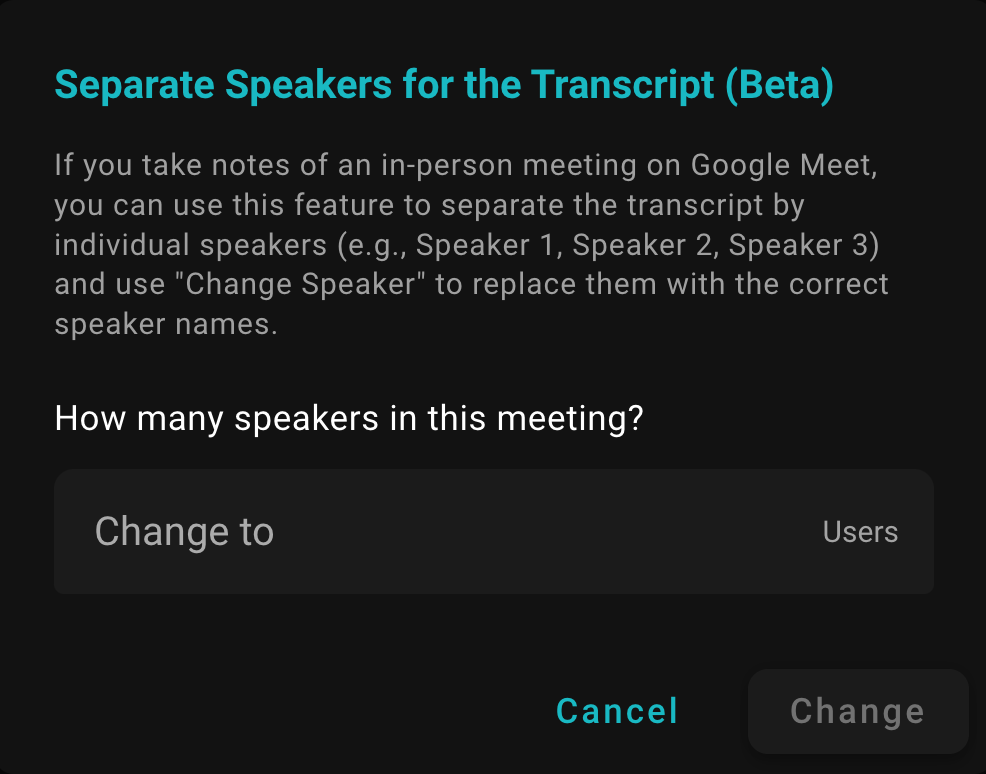
Dialog Identify Speakers SeaMeet pozwala określić liczbę mówców na spotkaniu. Wprowadzając rzeczywistą liczbę uczestników, SeaMeet używa diaryzacji audio do rozdzielenia transkryptu na indywidualnych mówców.

Diaryzacja mówców SeaMeet jest dość potężna, ale pamiętaj, że na tym etapie mówcy są tylko ponumerowani. Na przykład możesz zobaczyć etykiety Speaker 1 i Speaker 2, które są ogólne. Następnym krokiem będzie zastąpienie ich prawdziwymi imionami.
Zmiana etykiet mówców na prawdziwe imiona
Po początkowej identyfikacji będziesz chciał przypisać prawidłowe imiona do każdego mówcy. SeaMeet ułatwia to funkcją Change Speakers. Najpierw możesz posłuchać segmentów audio dla każdego zidentyfikowanego mówcy (SeaMeet pozwala odtworzyć tylko te części nagrania, gdzie, powiedzmy, Speaker 1 mówił). To pomaga potwierdzić, kim naprawdę jest Speaker 1 lub Speaker 2. Po rozpoznaniu głosu możesz wybrać odpowiednie imię uczestnika lub nawet utworzyć nowe imię, jeśli ta osoba nie była pierwotnie na liście uczestników.

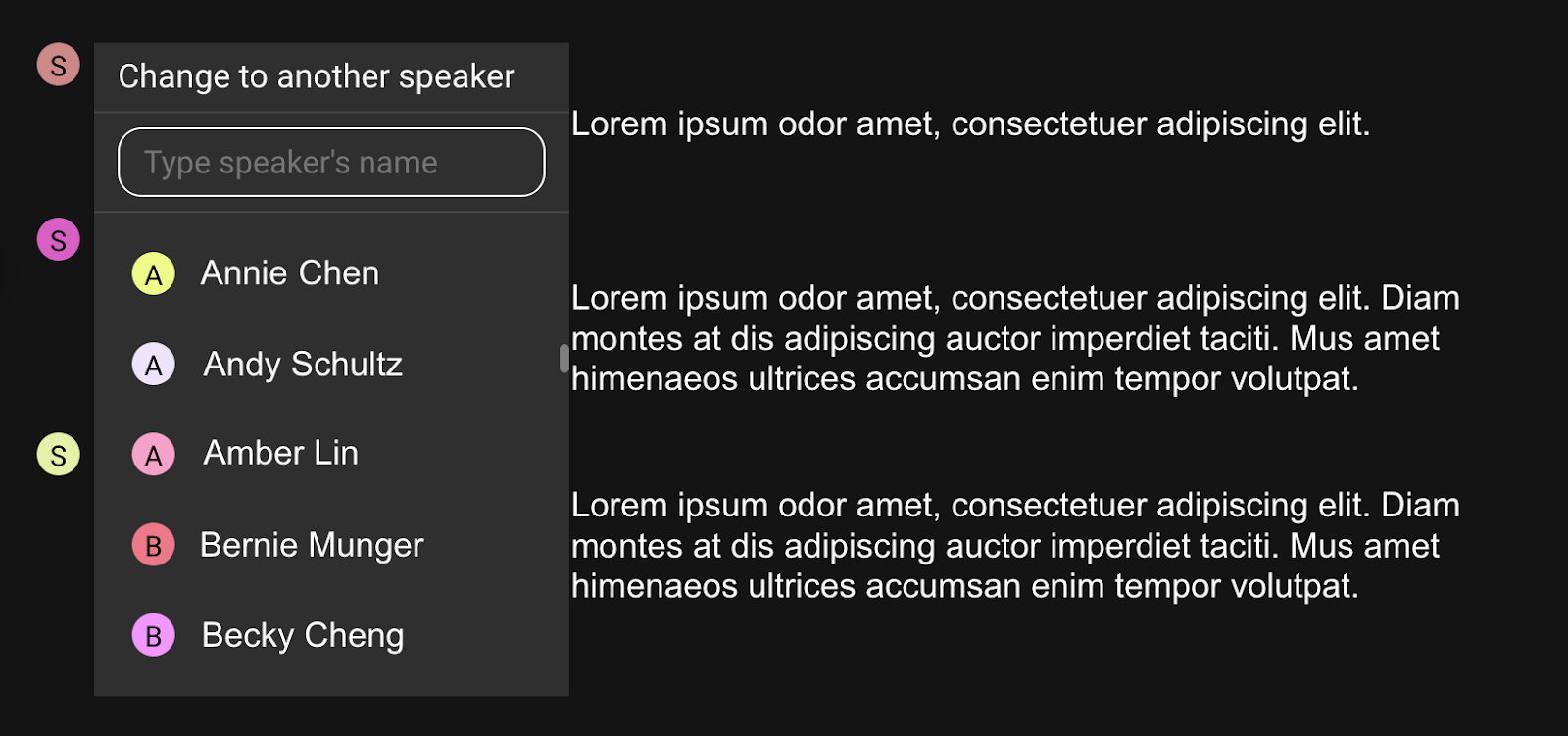
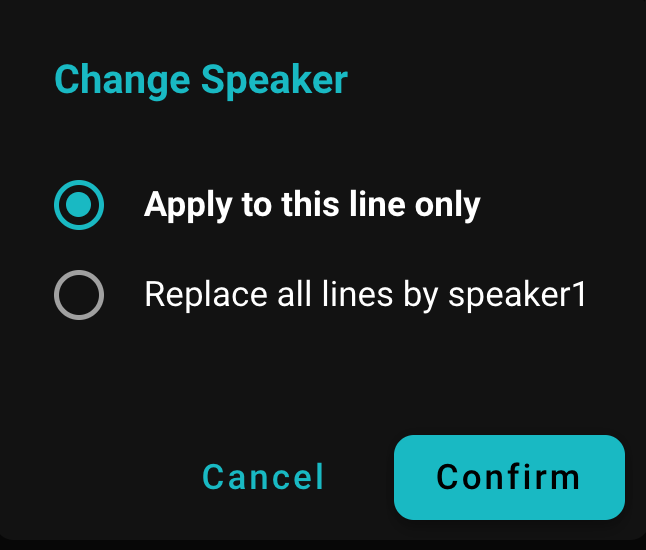
Podczas zmiany etykiety mówcy SeaMeet daje elastyczne opcje. Możesz wybrać zastąpienie tagu mówcy tylko dla konkretnej linii dialogu lub zastosować go do wszystkich wystąpień tego mówcy w całym transkrypcie. Na przykład, jeśli Speaker 1 to John Doe, możesz zastąpić tag mówcy jednej linii imieniem Johna lub zaktualizować każdą linię przypisaną do Speaker 1 za jednym razem. Po przejściu przez wszystkich mówców i zastąpieniu ogólnych etykiet prawdziwymi imionami, transkrypt zostanie odpowiednio zaktualizowany – teraz każda linia jest przypisana do właściwej osoby, znacznie poprawiając jasność zapisu.
Po użyciu “Change Speakers” do przypisania rzeczywistych imion, transkrypt jest aktualizowany z prawidłowymi imionami mówców. Na tym zrzucie ekranu etykiety zastępcze jak Speaker 1 zostały zastąpione prawdziwymi imionami uczestników, co ułatwia śledzenie rozmowy.
Ten krok zapewnia, że Twój transkrypt jest nie tylko technicznie dokładny, ale także przyjazny dla człowieka. Znacznie łatwiej czytać “John: Zaplanujmy spotkanie następne na przyszły tydzień.” niż niejasne “Speaker 1: Zaplanujmy następne…”, szczególnie podczas przeglądania spotkań później.
Regeneracja podsumowania spotkania z prawidłowymi mówcami
Jednym z wyróżników SeaMeet jest automatyczne podsumowanie spotkania. Początkowo AI-generowane podsumowanie może odnosić się do ludzi ogólnie (ponieważ nie znało imion wcześniej). Ale gdy Twój transkrypt ma prawidłowe imiona mówców, możesz zregenerować podsumowanie spotkania, aby odzwierciedlić te zmiany. Jednym kliknięciem przycisku “Regenerate Meeting Summary”, AI SeaMeet wyprodukuje nowe podsumowanie, które obejmuje prawidłowe imiona i atrybucje na podstawie dostosowanego transkryptu.
Podobnie jak proces identyfikacji mówców, regeneracja podsumowania działa w chmurze – możesz ją uruchomić, a następnie opuścić stronę i wrócić, gdy będzie gotowa. Zaktualizowane podsumowanie będzie czytane naturalnie, np. “John zaproponował nowy harmonogram projektu, a Jane zgodziła się przejrzeć plan,” zamiast używania symboli zastępczych. Ten spersonalizowany dotyk nie tylko ułatwia zrozumienie podsumowania, ale także czyni je bardziej użytecznym dla każdego, kto nie mógł uczestniczyć w spotkaniu.
Podsumowanie
Funkcja identyfikacji mówców SeaMeet wnosi profesjonalny polot do transkryptów spotkań osobistych. Rozdzielając mówców i oznaczając ich prawidłowymi imionami, zapewniasz, że wkład wszystkich jest jasno udokumentowany. W połączeniu z możliwością regeneracji podsumowań z tymi imionami, SeaMeet oszczędza czas i kłopoty w produkcji dokładnych zapisów spotkań. Przekształca chaotyczny surowy transkrypt w zorganizowany dialog, więc nigdy nie będziesz musiał grać w detektywa, zgadując, kto co powiedział. Czy to spotkanie zespołu, dyskusja panelowa, czy sesja burzy mózgów, pozwolenie SeaMeet na zarządzanie “kto co powiedział” pozwala skupić się na treści rozmowy – a to oznacza lepsze spotkania i lepsze wyniki.
Tagi
Gotowy, aby wypróbować SeaMeet?
Dołącz do tysięcy zespołów, które używają AI, aby uczynić swoje spotkania bardziej produktywnymi i wykonalnymi.