SeaMeet 說話人辨識:標註實體會議記錄中的發言者
目錄
在記錄實體會議(即所有與會者同處一室的會議)時,常面臨一項挑戰:錄音轉寫的文字混雜所有人的發言,卻無法辨識說話者身份。若您使用 Google Meet 錄製實體會議,所有聲音會被記錄為單一音源,轉錄文字通常呈現為未標註說話者的大段對話。SeaMeet 的說話人辨識功能正是為解決此問題設計,透過先進 AI 技術區分不同發言者,並允許您為每位說話者貼上正確姓名標籤,使會議記錄清晰易讀。
為何說話人辨識對會議記錄至關重要?
當會議中有多位發言者時,未區分說話者的逐字稿將難以閱讀——您可能看到冗長對話串,卻無法判斷每句話的發言者。準確記錄「誰說了什麼」對會後整理紀要與任務追蹤極為關鍵。SeaMeet 運用語音分離(說話人分離)技術解決此問題:系統分析音頻中的聲紋變化,並根據您提供的與會人數,將對話按發言者拆分。拆分後轉錄內容將出現「說話人1、說話人2、說話人3」等標籤對應不同發言者。需注意此功能在 2-6 人會議效果最佳,人數過多時準確率可能下降。
在實體會議中自動辨識說話人
使用 SeaMeet 的說話人辨識工具非常簡單:
- 首先告知系統本次會議參與人數
- SeaMeet 將據此人數重新拆分逐字稿,按指定人數劃分不同說話者段落
- 系統自動判定同屬一位說話者的句子,並標註「說話人1、說話人2」等佔位標籤
辨識過程為自動化處理,您無需停留在頁面等待。完成後轉錄文字將分段標註說話人編號,會議對話輪廓一目了然。
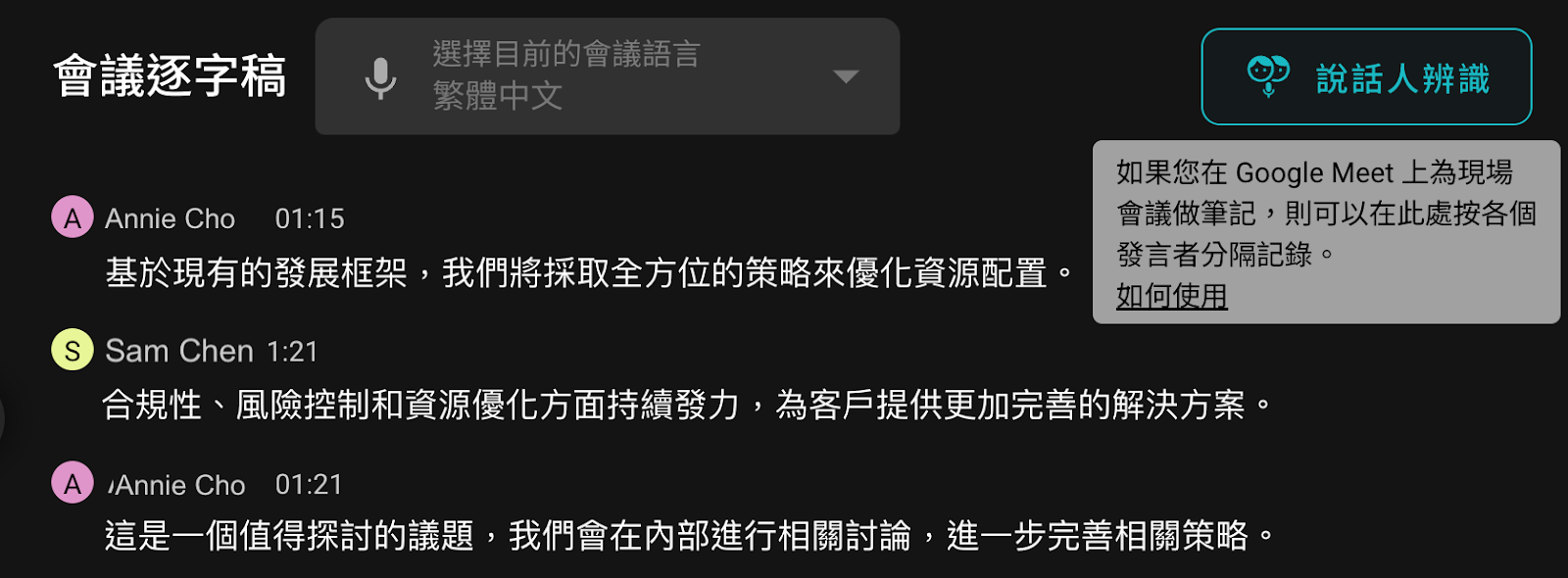
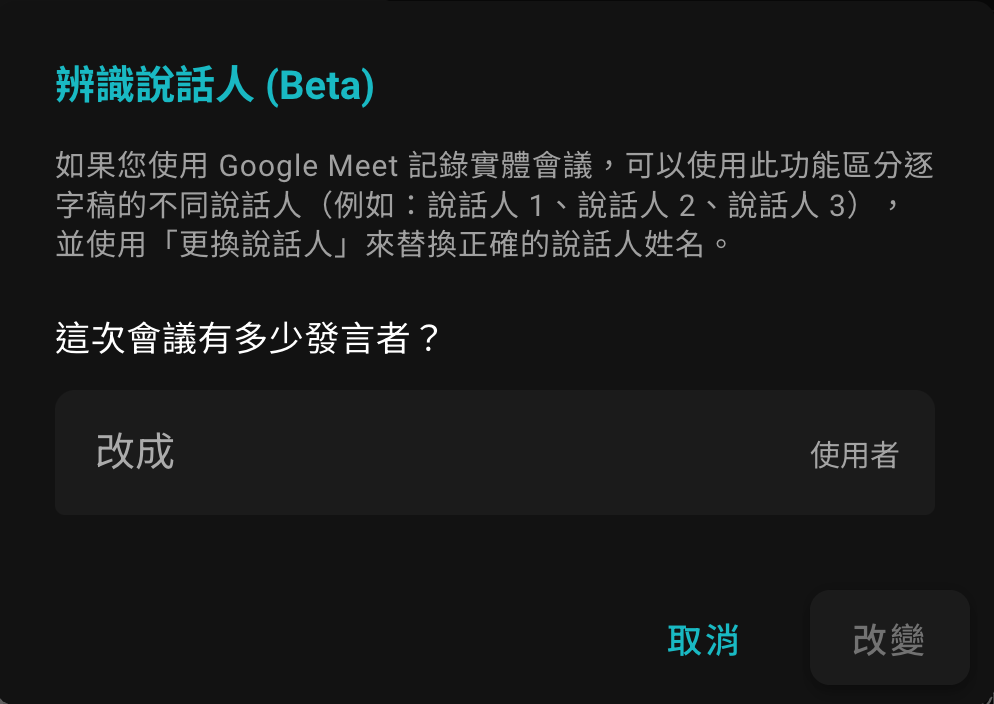

SeaMeet 說話人辨識對話框:輸入與會人數即可啟動語音分離流程
需特別說明,此階段系統僅以數字編號區分說話人(例如說話人1、說話人2),尚未知曉真實身份。接下來您可將這些編號替換為實際姓名。

將說話人編號替換為姓名標籤
完成初步辨識後,您已獲得按人分段的逐字稿。接著使用變更說話人功能,將通用編號替換為正確姓名:
- 點擊每位「說話人」旁的播放圖示,聆聽系統分離出的專屬錄音片段
- 透過片段確認發言者身份(例如「說話人1」實際是會議中的張三)
- 從與會者名單選擇對應姓名,或新建姓名標籤

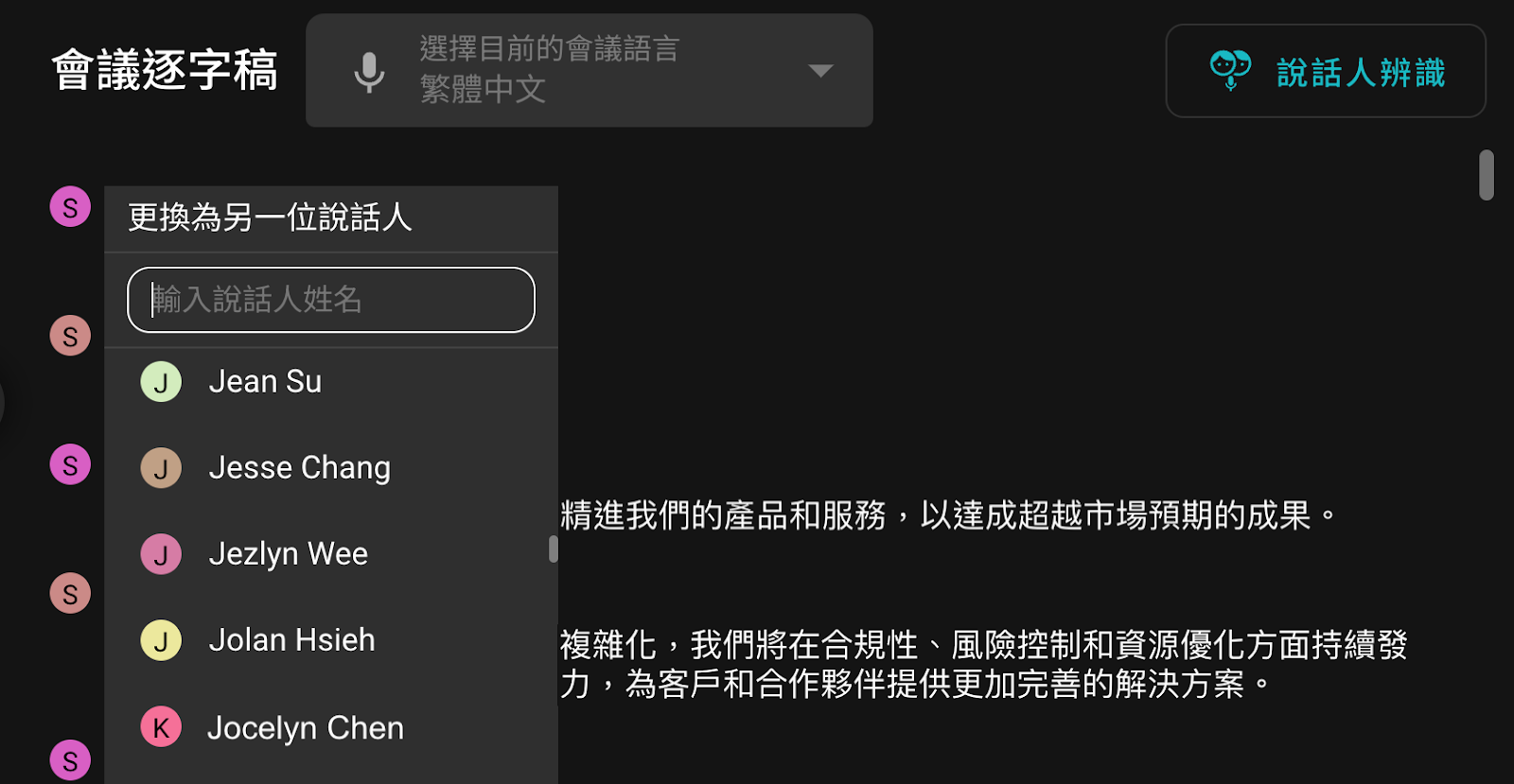
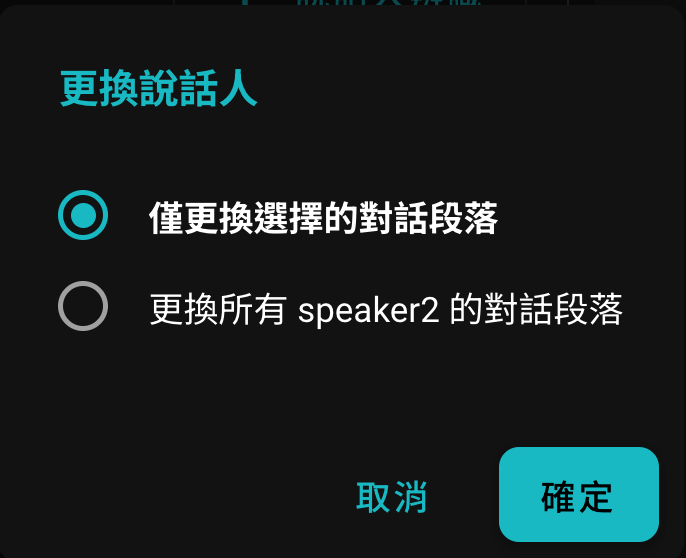
替換時提供兩種模式: ▸ 僅替換當前行:單一對話行的標籤更新 ▸ 套用至全文:整場會議中該說話人的所有標籤同步更新
例如確認「說話人1」即為張三後,選擇「套用至全文」,所有「說話人1」標籤將統一替換為「張三」。依此方式處理完所有說話人,逐字稿每行對話旁皆顯示真實姓名,冰冷編號轉為熟悉人名。
替換後逐字稿:說話人編號已更新為真實姓名
此時您的會議記錄不僅轉寫精準,更明確標示每句話的發言者。後續整理紀要或向未與會者簡報時,將大幅提升可讀性與專業度。
重新生成含正確姓名的會議摘要
SeaMeet 的AI 會議摘要功能在最初生成時,因未辨識說話人身份,摘要可能使用籠統稱謂。當逐字稿已標註真實姓名後,您可點擊「重新產生會議摘要」,系統將基於更新後的逐字稿生成全新摘要:
- AI 引擎讀取含正確姓名的完整記錄
- 產出標註發言者身份的摘要報告(例如:「張三提出新專案時程,李四同意審核計畫…」)
此過程同樣在雲端非同步完成,無需停留頁面等待。稍後返回會議記錄頁面,即可查看標示人員身份的新摘要,讓行動項目與建議來源更加明確。
總結
透過 SeaMeet 說話人辨識功能,實體會議記錄整理變得高效且專業:
✓ 智能分離發言:消除猜測說話人的困擾 ✓ 真實姓名標註:提升記錄可信度與可讀性 ✓ 動態摘要更新:確保會議要點關聯正確人員
無論團隊會議、圓桌討論或腦力激盪,SeaMeet 皆能快速釐清「誰說了什麼」,讓您專注於會議內容本質,大幅提升紀要整理效率與品質。專業會議記錄無需繁瑣人工處理,SeaMeet 自動化流程讓會議產出全面升級。