SeaMeet 화자 식별: 대면 회의 기록에서 화자를 식별하고 라벨링
목차
대면 회의(참가자들이 같은 방에 있는)의 전사는 어려울 수 있습니다. Google Meet를 사용하여 세션을 녹음하는 경우, 모든 목소리가 하나의 오디오 채널에 캡처되어 누가 무엇을 말했는지 파악하기 어렵습니다. SeaMeet의 화자 식별 기능은 이 문제를 해결하기 위해 설계되었습니다. 고급 AI를 활용하여 회의 기록에서 화자를 구분하고 올바른 이름을 할당할 수 있어, 논의에 대한 명확하고 읽기 쉬운 기록을 얻을 수 있습니다.
회의에서 화자 식별이 중요한 이유
다중 화자 회의에서, 원시 기록은 매우 빠르게 혼란스러워질 수 있습니다 - 화자 변경을 나타내는 표시가 없는 긴 텍스트 블록을 볼 수 있습니다. 정확한 회의록과 후속 조치를 위해 누가 각 댓글을 말했는지 아는 것이 중요합니다. SeaMeet는 오디오 다이어리제이션(다른 사람들이 언제 말하고 있는지 감지하는 AI 프로세스)을 통해 이를 해결합니다. 참가자 수를 지정함으로써, SeaMeet는 기록을 각 화자의 세그먼트(예: 화자 1, 화자 2, 화자 3)로 분리할 수 있습니다. 이 기능은 약 2-6명의 회의에서 최적의 정확도를 위해 가장 잘 작동합니다.
대면 회의에서 화자 식별
SeaMeet의 화자 식별 도구 사용은 간단합니다. 회의에 몇 명이 있었는지 표시하는 것부터 시작합니다. SeaMeet는 그 후 그 수에 따라 전체 기록을 다시 분할합니다. 시스템은 녹음을 통과하며 화자별로 대화를 그룹화하고, 각 세그먼트에 화자 1, 화자 2 등과 같은 임시 이름으로 라벨을 붙입니다. 이 식별 과정 동안 기다릴 필요가 없습니다 - 회의 인터페이스를 떠나고 나중에 돌아올 수 있으며, SeaMeet는 백그라운드에서 계속 처리합니다. 완료되면 기록이 깔끔하게 분할되고 다른 화자로 라벨링되어 있는 것을 볼 수 있으며, 대화의 초기 다이어리제이션을 얻게 됩니다.
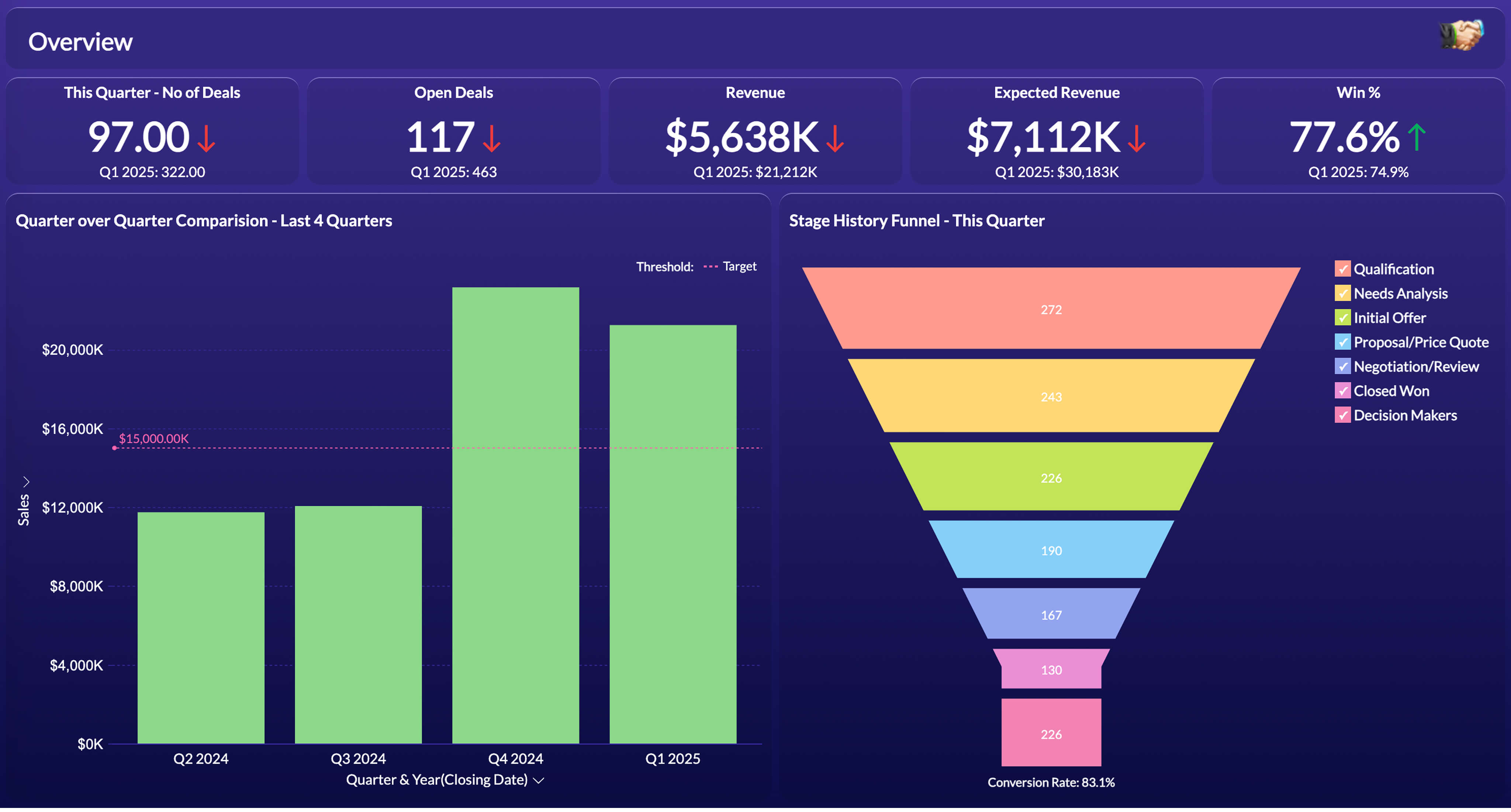
SeaMeet의 화자 식별 대화상자를 통해 회의의 화자 수를 지정할 수 있습니다. 실제 참가자 수를 입력함으로써, SeaMeet는 오디오 다이어리제이션을 사용하여 기록을 개별 화자로 분리합니다.

SeaMeet의 오디오 다이어리제이션은 꽤 강력하지만, 이 단계에서 화자들은 단지 번호가 매겨져 있다는 것을 기억하세요. 예를 들어, 화자 1과 화자 2 라벨을 볼 수 있지만, 이들은 일반적입니다. 다음 단계는 이것들을 실제 이름으로 바꾸는 것입니다.
화자 라벨을 실제 이름으로 변경
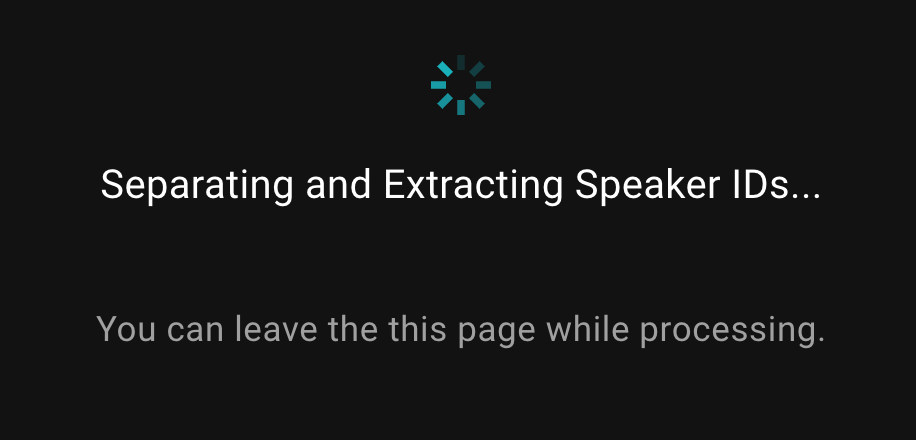
초기 식별 후, 각 화자에게 올바른 이름을 할당하고 싶을 것입니다. SeaMeet는 ‘화자 변경’ 기능으로 이를 쉽게 만듭니다. 먼저, 식별된 각 화자의 오디오 세그먼트를 들을 수 있습니다(SeaMeet는 예를 들어 화자 1이 말하고 있던 녹음의 부분만 재생할 수 있게 합니다). 이것은 화자 1이나 화자 2가 실제로 누구인지 확인하는 데 도움이 됩니다. 목소리를 인식하면, 적절한 참가자의 이름을 선택하거나 그 사람이 원래 참가자 목록에 없었다면 새로운 이름을 만들 수도 있습니다.

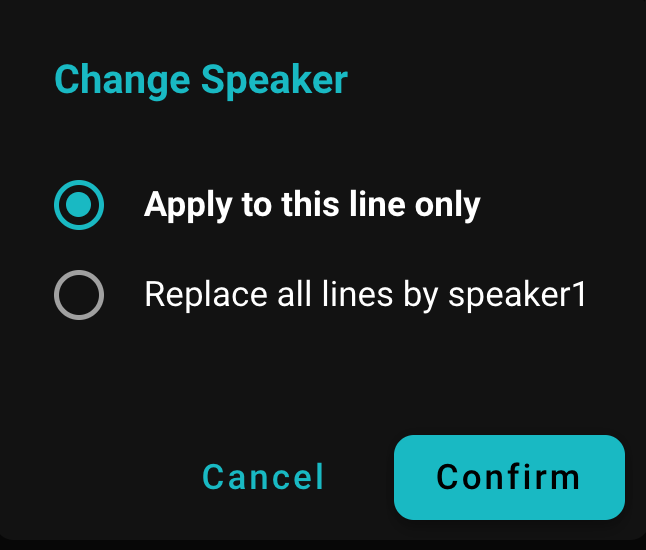
화자 라벨을 변경할 때, SeaMeet는 유연한 옵션을 제공합니다. 특정 대화 행의 화자 태그만 바꾸거나, 전체 기록에서 그 화자의 모든 인스턴스에 적용할 수 있습니다. 예를 들어, 화자 1이 John Doe라면, 한 행의 화자 태그를 John의 이름으로 바꾸거나, 화자 1에 귀속된 모든 행을 한 번에 업데이트할 수 있습니다. 모든 화자를 거쳐 일반적인 라벨을 실제 이름으로 바꾼 후, 기록은 그에 따라 업데이트됩니다 - 이제 모든 행이 올바른 사람에게 귀속되어 기록의 명확성이 크게 향상됩니다.
‘화자 변경’을 사용하여 실제 이름을 할당한 후, 기록은 올바른 화자 이름으로 업데이트됩니다. 이 스크린샷에서, 화자 1과 같은 플레이스홀더 라벨이 실제 참가자 이름으로 바뀌어 대화를 따라가기 쉽게 만들었습니다.
이 단계는 기록이 기술적으로 정확할 뿐만 아니라 인간에게 친숙하다는 것을 보장합니다. “John: 다음 주에 후속 회의를 일정 잡자.”를 읽는 것이 모호한 “화자 1: 후속 회의를 일정 잡자…”를 읽는 것보다 훨씬 쉽습니다. 특히 나중에 회의를 검토할 때 그렇습니다.
올바른 화자로 회의 요약 재생성
SeaMeet의 하이라이트 중 하나는 자동 회의 요약입니다. 초기에는, AI 생성 요약이 사람들을 일반적으로 참조할 수 있습니다(이전에 이름을 몰랐기 때문에). 하지만 기록에 올바른 화자 이름이 포함되면, 회의 요약을 재생성하여 이러한 변경사항을 반영할 수 있습니다. ‘회의 요약 재생성’ 버튼을 클릭하면, SeaMeet의 AI는 조정된 기록을 기반으로 적절한 이름과 귀속을 포함한 새로운 요약을 생성합니다.
화자 식별 프로세스와 마찬가지로, 요약 재생성은 클라우드에서 실행됩니다 - 트리거한 후 페이지를 떠나고, 완료되면 돌아올 수 있습니다. 업데이트된 요약은 자연스럽게 읽힙니다. 예를 들어, “John이 새로운 프로젝트 타임라인을 제안했고, Jane이 계획을 검토하는 것에 동의했습니다.” 등으로, 플레이스홀더를 사용하는 대신입니다. 이 개인화된 터치는 요약을 이해하기 쉽게 만들 뿐만 아니라, 회의에 참석할 수 없었던 사람에게도 더 유용하게 만듭니다.
결론
SeaMeet의 화자 식별 기능은 대면 회의 기록에 전문적인 마무리를 가져옵니다. 화자를 분리하고 올바른 이름으로 라벨링함으로써, 모든 사람의 기여가 명확하게 문서화되도록 보장합니다. 이러한 이름으로 요약을 재생성하는 기능과 결합하여, SeaMeet는 정확한 회의 기록을 만드는 시간과 번거로움을 절약합니다. 혼란스러운 원시 기록을 정리된 대화로 변환하므로, 누가 무엇을 말했는지 추측하는 탐정 놀이를 할 필요가 없습니다. 팀 회의, 패널 토론, 브레인스토밍 세션이든 상관없이, SeaMeet에게 “누가 무엇을 말했는지”를 처리하게 하면 대화의 내용에 집중할 수 있습니다 - 그것은 더 나은 회의와 더 나은 결과를 의미합니다.