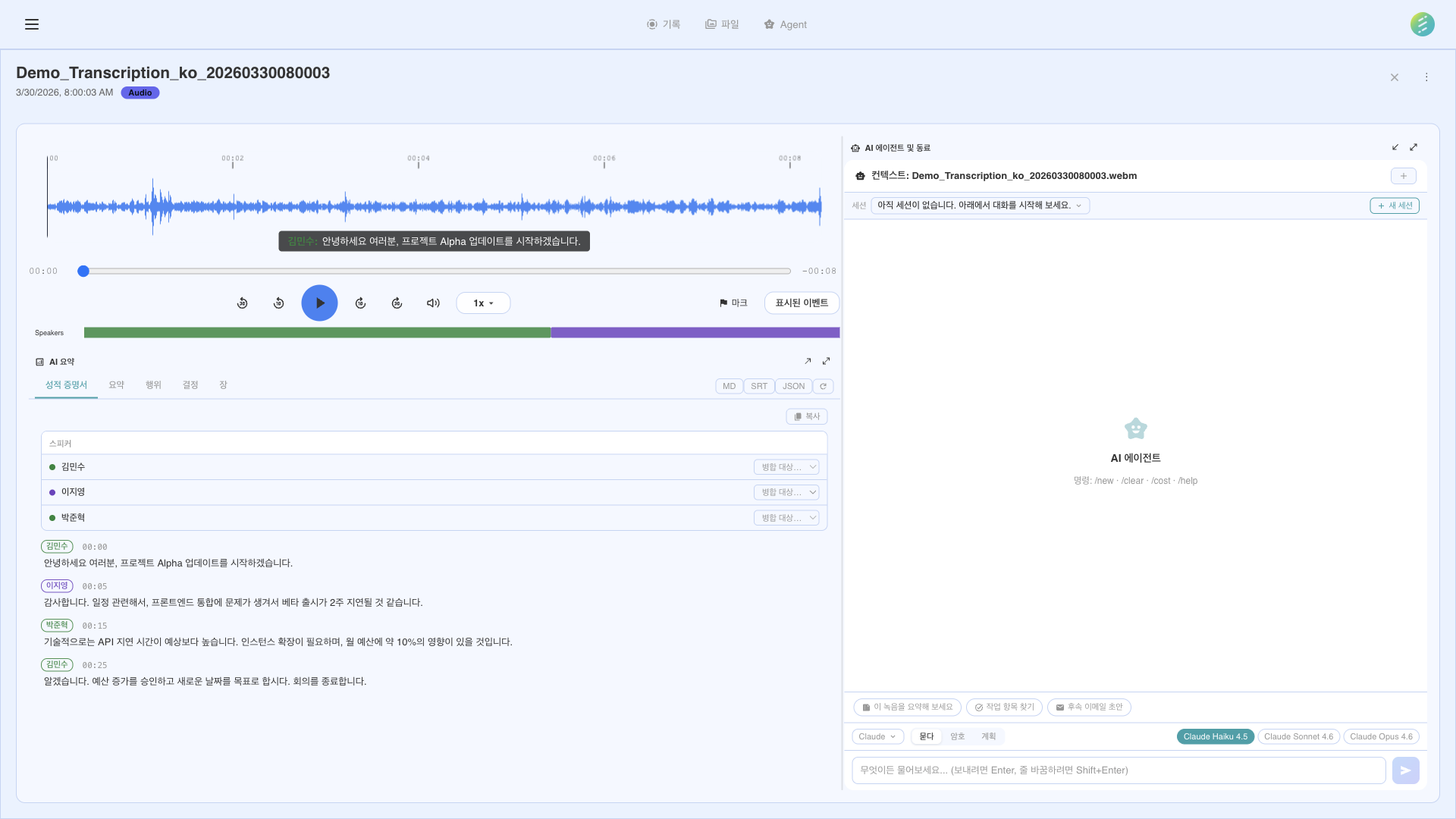
AI 기반 음성 인식 및 분석 인터페이스
작동 방식
음성 인식을 활성화하고 녹음을 시작하면 SeaMeet이 오디오를 Gemini API로 실시간 스트리밍합니다. AI 모델이 음성을 처리하고 자동 언어 감지와 화자 분리를 통해 몇 초 내에 텍스트를 반환합니다.
녹음 중 실시간
음성 인식은 녹음 중 실시간으로 이루어집니다. 발화 후 몇 초 내에 텍스트가 표시됩니다 — 녹음 종료 후가 아닙니다.
20개 이상 언어 지원
자동 언어 감지로 수동 언어 설정이 불필요합니다. SeaMeet이 사용 중인 언어를 식별하고 적절하게 텍스트로 변환합니다.
화자 감지
SeaMeet은 서로 다른 화자를 구별하고 각 세그먼트에 라벨을 붙입니다. 다수의 참가자가 있는 미팅에서 누가 무엇을 말했는지 확인할 수 있습니다.
타임스탬프 세그먼트
모든 음성 인식 세그먼트에 정확한 타임스탬프가 포함됩니다. 타임스탬프를 클릭하면 녹음의 해당 순간으로 이동합니다.
캡션 오버레이
녹음 중 화면에 실시간 캡션을 오버레이 표시. 접근성, 시끄러운 환경, 스피커를 사용할 수 없는 경우에 유용.
다중 제공업체 STT
여러 음성-텍스트 변환 제공업체 중에서 선택할 수 있습니다: Gemini Live(기본값), Deepgram Nova-3, Soniox, OpenAI Realtime. 속도, 정확도, 언어 지원 필요에 따라 제공업체를 전환하세요.
SRT 내보내기
트랜스크립트를 SRT 자막 파일로 내보냅니다. 비디오 편집, 공유, 다른 도구로 가져오기에 활용하세요.
중국어 변환
자동 후처리를 통해 간체 중국어(zh-CN) 트랜스크립트를 번체 중국어(zh-TW)로 변환하여 수동 변환 단계를 생략합니다.
프라이버시 관련 고려사항
오디오 스트리밍
음성 인식이 활성화된 동안 오디오는 처리를 위해 AI 제공업체로 스트리밍됩니다. 오디오는 제공업체에 저장되지 않으며 처리 후 삭제됩니다.
트랜스크립트는 로컬 저장
생성된 음성 인식 텍스트는 기기에 로컬 저장됩니다. SeaMeet이 트랜스크립트를 자체 서버에 업로드하지 않습니다.
옵트인 방식만
음성 인식은 기본적으로 활성화되지 않습니다. 녹음별로 또는 전역 설정으로 활성화 시점을 선택할 수 있습니다.
Not on the desktop app? See the web capability → Transcription