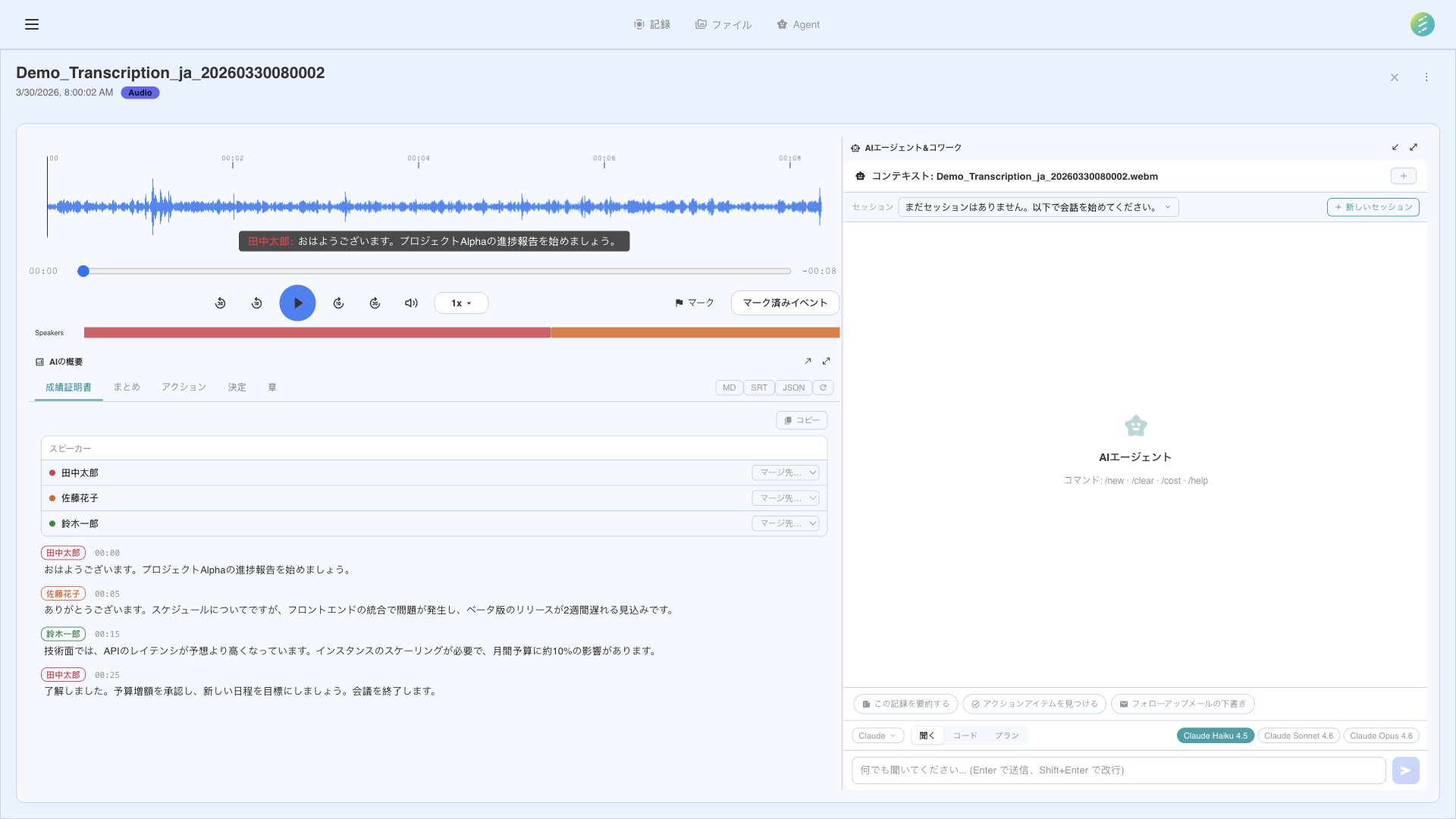
AI による文字起こしと分析インターフェース
仕組み
文字起こしを有効にして録音を開始すると、SeaMeet は音声を Gemini API にリアルタイムでストリーミングします。AI モデルが音声を処理し、自動言語検出と話者分離を行い、数秒以内にテキストを返します。
録音中のリアルタイム
文字起こしは録音中にライブで行われます。発話から数秒以内にテキストが表示されます — 録音終了後ではありません。
20 以上の言語に対応
自動言語検出により、手動での言語設定が不要です。SeaMeet が話されている言語を識別し、適切に文字起こしします。
話者検出
SeaMeet は異なる話者を区別し、各セグメントにラベルを付けます。複数の参加者がいるミーティングでは、誰が何を言ったかを確認できます。
タイムスタンプ付きセグメント
すべての文字起こしセグメントに正確なタイムスタンプが含まれます。タイムスタンプをクリックすると、録音のその瞬間にジャンプします。
キャプション表示
録音中に画面上にライブキャプションをオーバーレイ表示。アクセシビリティ、騒がしい環境、スピーカーが使えない場合に便利。
マルチプロバイダー STT
複数の音声認識プロバイダーから選択可能:Gemini Live(デフォルト)、Deepgram Nova-3、Soniox、OpenAI Realtime。速度、精度、言語サポートのニーズに応じてプロバイダーを切り替え。
SRT エクスポート
トランスクリプトを SRT 字幕ファイルとしてエクスポート。動画編集、共有、他のツールへのインポートに活用。
中国語変換
録音後の自動後処理で簡体字中国語(zh-CN)のトランスクリプトを繁体字中国語(zh-TW)に変換。手動変換の手間を省きます。
プライバシーに関する注意事項
音声ストリーミング
文字起こしがアクティブな間、音声は処理のために AI プロバイダーにストリーミングされます。音声はプロバイダーに保存されず、処理後に削除されます。
トランスクリプトはローカルに保存
生成された文字起こしテキストはお使いの端末にローカル保存されます。SeaMeet がトランスクリプトを自社サーバーにアップロードすることはありません。
オプトイン方式のみ
文字起こしはデフォルトでは有効になりません。録音ごと、またはグローバル設定として、有効にするタイミングを選択できます。
Not on the desktop app? See the web capability → Transcription